

Alle Experten sind sich einig: Wir werden noch lange mit dem Coronavirus leben müssen. Bis Medikamente und Impfstoffe zur Verfügung stehen, werden Einschränkungen und Vorsichtsmaßnahmen weiterhin unser tägliches Leben prägen. Große Hoffnungen für den Weg zurück in eine relative Normalität werden dabei auf die „Corona-App“ gesetzt. Genauer gesagt: in eine Tracing-App. Sie soll dabei helfen, Infektionswege aufzuspüren und Personen zu warnen, die vorher mit möglicherweise Infektiösen Kontakt hatten. Eine wichtige Forderung an eine solche App ist, dass sie die Privatheit ihrer Nutzer gewährleisten muss. Beim Streit um die Frage, ob Kontaktdaten zentral oder dezentral gespeichert werden, äußerten Sicherheitsforscher und Datenschützer große Bedenken gegen das zentrale Modell. Doch warum eigentlich – wenn doch die Kontaktdaten ohnehin anonymisiert sind? Wer Antworten sucht, sollte das Konzept „Social Graph“ kennen.
Autor: Stefan Achleitner; Aufmacherbild: (C) Pixabay/Gert Altmann
Bei der Lockerung von Ausgangsbeschränkungen und Einschränkungen des täglichen Lebens steht die Politik vor einem schwierigen Balanceakt: Einerseits soll ein Anstieg der Infektionsraten unbedingt verhindert werden. Andererseits müssen das Leben und die Wirtschaft aber auch langsam wieder zur Normalität zurückkehren. Weithin Einigkeit herrscht darüber, dass eine Corona-Tracing-App dabei helfen kann. Doch damit endet die Übereinstimmung auch schon. Denn ein großer Streit entbrannte um die Frage, wie die von einer solchen App erfassten Kontaktinformationen gespeichert werden sollen: Zentral oder dezentral?
Das Funktionsprinzip der „Corona-App“
Grundsätzlich soll eine „Corona-App“ erfassen, wem ihr Nutzer in den letzten rund 14 Tagen nahe gekommen ist. Diese Erfassung nutzt den Kurzstreckenfunk Bluetooth. Anhand seiner Signalstärke kann eine Tracing-App abschätzen, wie groß der Abstand zum anderen Gerät – und somit seinem Besitzer – in etwa ist. Dazu sind zwar für jedes Smartphone-Modell spezielle Adaptionen erforderlich. Zudem müssen die Betriebssystem-Anbieter Apple und Google entsprechende Schnittstellen bereitstellen und Sicherheitseinschränkungen für diesen speziellen Zweck aufheben. Doch diese Fragen sind grundsätzlich gelöst.
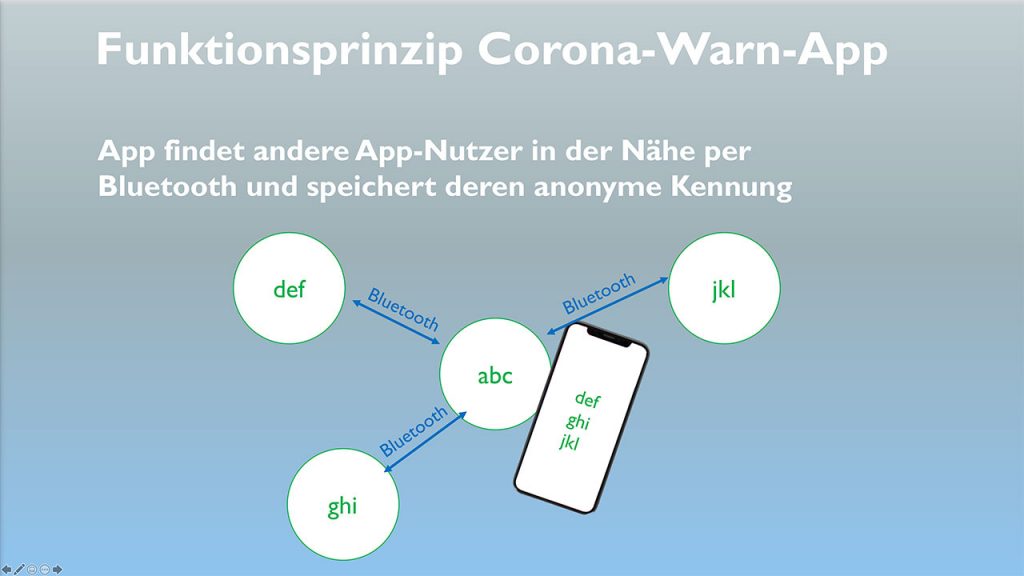
Der Zweck der Übung: Die App erfasst anhand anonymisierter IDs, mit wem man wann wie lange Kontakt hatte. Wird bei einem Nutzer der App eine Infektion mit dem Corona-Virus erkannt, soll die App alle in der möglichen Ansteckungszeit erfassten Kontakte warnen. Dazu muss sie die Information, dass ein Nutzer positiv getestet wurde auf jeden Fall auf einen zentralen Server hochladen. Von dort aus erfolgt dann eine Warnung aller anderen Nutzer, die dieser infektiösen Person begegnet waren. Dabei sieht das Konzept vor, dass ein Arzt die Meldung bestätigen muss – beispielsweise durch einen Code. Dies soll sicherstellen, dass niemand wissentlich Falschmeldungen hochlädt.
Zentral oder dezentral – wo liegen die Kontaktdaten?
Der Streit der Datenschutz-Experten dreht sich nun im Wesentlichen um die Frage, was genau auf dem Server gespeichert wird – und was nicht. Die unterschiedlichen Ansätze:
Zentrales Modell: Neben den anonymen ID des Nutzers wandern auch die IDs seiner Begegnungen auf den Server. Dieser ermittelt dann möglicherweise infektiöse Kontakte. Der Server schickt dann die IDs von möglicherweise Betroffenen an die Apps.

Dezentrales Modell: Die ID eines Nutzers wandert nur dann auf den Server, wenn er erkrankt ist. Die IDs seiner Begegnungen bleiben hingegen auf dem Smartphones jedes Nutzers gespeichert. Der Server sendet dann regelmäßig die IDs positiv getesteter Personen an alle Nutzer der App. Diese überprüft dann lokal, ob eine der gemeldeten IDs in der eigenen Kontaktliste zu finden ist.

Ab diesem Punkt läuft es bei beiden Varianten wieder gleich: Wer im kritischen Zeitraum Kontakt zu einem als infektiös erkannten Nutzer hatte, wird von der App gewarnt. Er sollte sich nun selbst testen lassen und beispielsweise Kontakte zu Risikogruppen vermeiden.
Beide Modelle haben Vor- und Nachteile. Eine zentrale Speicherung ist aus wissenschaftlicher Sicht durchaus sinnvoll. Denn durch die gewonnen Daten lassen sich wichtige Einblicke zur Ausbreitung des Corona-Virus gewinnen. Das ist nicht nur zur Ermittlung der viel zitierten Basiseproduktionszahl R hilfreich. Es könnte auch gezielte Maßnahmen unterstützen, um eine weitere Verbreitung zu verhindern. Doch Datenschützer befürchten bei der zentralen Variante, dass die Privatheit der Nutzer nicht ausreichend sichergestellt ist. Dies wiederum gilt als wesentlicher Vorteil der dezentralen Variante: Sie bietet den größeren Schutz der Kontaktdaten im Hinblick auf die Privatsphäre.
Social Graphs: Worin liegen die Risiken zentral gesammelter Annäherungs-Daten?
Doch warum genau stellt die zentrale Speicherung der sogenannten Proximity-Daten (also Annäherungs- oder Begegnungs-Daten) eigentlich ein Risiko dar? Schließlich sind die IDs doch anonym und sollen überdies regelmäßig – beispielsweise im Wochenrhythmus – gewechselt werden.
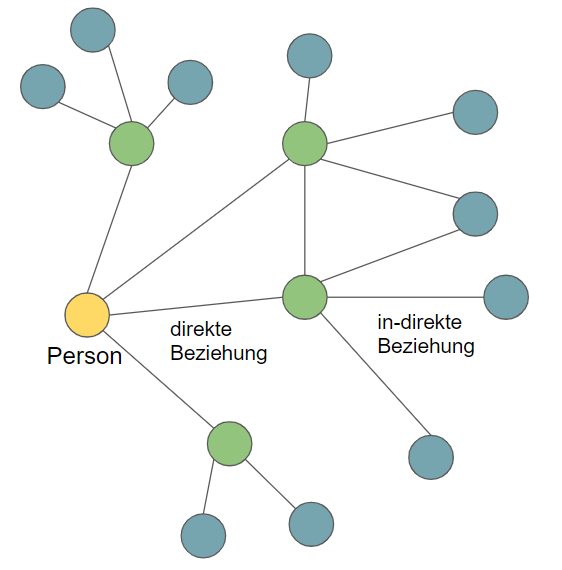
Kritiker des zentralen Modells führen in diesem Zusammenhang vor allem das Risiko von „Social Graphs“ an. Generell sind Social Graphs eine mathematische Darstellung unserer sozialen Kontakte, wie im Bild unten dargestellt.
Wie in einem sozialen Netzwerk wie etwa Facebook gibt es dabei direkte Beziehungen (Freunde) oder indirekte Beziehungen (Freunde von Freunden). Welche Menschen man kennt, mit welchen man viel Zeit verbringt oder zu bestimmten Zeitpunkten trifft, sagt viel über eine Person aus. Und genau diese Daten sammelt ja die Corona-Tracing-App.
Obwohl die IDs anonym sind, können Proximity-Daten viel über eine Person verraten – vor allem in Zusammenhang mit zeitlicher Information. Auch ohne eine Verknüpfung der IDs zu persönlichen Daten wie Name, Adresse, Username oder Ausweisnummer, lässt sich auf ihrer Basis ein detaillierter Social Graph erstellen.
Ein Social Graph verrät dann zum Beispiel schnell unsere Familienmitglieder beziehungsweise Personen, die im selben Haushalt leben. Denn hier werden regelmäßige Proximity-Einträge beziehungsweise ein Link im Social Graph morgens und abends erstellt. Weitere direkte Verbindungen im Social Graph einer Person können Hinweise geben, mit wem man zusammenarbeitet, welchen Vereinen man angehört oder auch welche politische Gesinnung man hat. Wird aus dem Social Graph einer Person zum Beispiel ersichtlich, dass jemand häufig mit Angehörigen einer bestimmten politischen Partei Kontakt hat, liegt die Annahme nicht fern, dass die Person sich auch zu dieser Partei hingezogen fühlt.
Spionieren mit dem Social Graph: Anonymisierte Kontakte lassen sich schnell de-anonymisieren
Dasselbe Denkmuster lässt sich auf Sportvereine, Unternehmen oder andere Interessengruppen anwenden. Hat man Zugang zu einer Datenbank von Social Graphs, lassen sich trotz anonymisierter IDs Personen sehr genau identifizieren. Und somit auch ihre Identität rekonstruieren. Techniken zur De-Anonymisierung solcher Daten basieren oft auf dem Vergleich mehrerer Teilgraphen. Wer tiefer in die dahinter liegenden Überlegungen und Verfahren einsteigen möchte, findet eine ausführliche Beschreibung im Paper “An Automated Social Graph De-anonymization Technique“, das von Forschern der Universität Cambridge und des University College London verfasst wurde.
Das Grundprinzip kann man aber auch sehr einfach selbst anhand der eigenen Social-Network-Kontakte nachvollziehen: Arbeitet man beispielsweise in der IT-Industrie, wird ein überdurchschnittlicher Prozentsatz der Kontakte vermutlich auch aus dieser Industrie kommen. Spielt man Fußball in einem Verein, werden viele Facebook-Freunde vermutlich auch an Fussball interessiert sein.
Untersuchungen von Wissenschaftlern der New York University haben in dem Paper „Facebook Users Have Become Much More Private: A Large-Scale Study“ gezeigt, dass bei sozialen Netzwerken wie Facebook immer mehr Nutzer auf dieses Phänomen reagieren und zum Beispiel ihre Freundesliste verstecken.
Auch Cybergangster kennen das Instrument Social Graph
Die Bedenken, die Sicherheitsexperten gegen die zentrale Speicherung von Kontaktdaten durch eine „Corona-App“ haben, richten sich dabei keineswegs nur gegen Regierungen und Behörden. Zwar ist auch nicht völlig abwegig, dass Ermittlungs- und Gesundheitsbehörden, Geheimdienste oder andere staatliche Stellen die auf entsprechenden Servern gespeicherten Daten zweckentfremden könnten. Doch noch viel riskanter ist die missbräuchliche Nutzung solcher Datenschätze durch Cyberkriminelle. Gelänge ihnen ein Diebstahl dieser kritischen Daten, könnten auch sie die beschriebenen Techniken anwenden.
Beschäftigt man sich mit modernen Cyberangriffen, steht am Anfang einer Attacke oft „Social Engineering”. Dabei nutzen die Cyberkriminellen das Vertrauen der Zielperson aus. Sie verleiten sie etwa durch einen Telefonanruf oder eine Phishing-Mail zu einer bestimmten Aktion. E-Mails oder Anrufe, die vermeintlich von einem Familienmitglied oder einem Arbeitskollegen stammen, haben dabei eine viel höhere Erfolgschance. Sie können dann beispielsweise zum Klick auf einen kompromittierten Link oder zur Installation einer Schadsoftware führen. Oder auch zum Herausgeben von Zugangsdaten beziehungsweise PINs oder Passwörtern.
Durch die Auswertung von Social Graphs könnten Cybergangster solche Angriffe mittels Social Engineering gezielt konstruieren und oftmals erfolgreich einsetzen. Diese Vorgehensweise nennt sich auch Spear-Phishing.
Design und Implementierung einer „Corona-App“ sind entscheidend
Auch wenn es vertrauenswürdige Behörden oder Institutionen sind, die die Daten speichert, gilt der Grundsatz: Hundertprozentige Sicherheit gibt es nicht. Der Vorteil eines dezentralen Systems: Auf einem einzelnen Smartphone liegen immer nur die Kontaktdaten eines einzelnen Nutzers. Zwar besteht auch hier das Risiko eines unberechtigten Zugriffs, etwa durch Sicherheitslücken oder kompromittierte Apps. Doch wenn man sich die Folgen eines Datendiebstahls ausmalt, der alle Nutzer einer Corona-Tracing-App betreffen würde, wird schnell klar, warum die dezentrale Lösung als weniger riskant gilt.
Weiter steigern lässt sich die Sicherheit des Konzepts, wenn die Tracing App Techniken wie „Differential Privacy“ berücksichtigt. Dieses Verfahren kann die von Social Graphs repräsentierten Kontakte weiter anonymisieren. Wie ein solches Verfahren funktioniert, haben Forscher der Universität Berkeley in ihrem Paper “Preserving Link Privacy in Social Network Based Systems” vorgestellt.
In jedem Fall kommt es also auf die konkrete Implementierung und das Design einer Corona-Tracing-App an. Dass eine solche App grundsätzlich große Chancen und Vorteile bietet, steht dabei außer Frage. Nicht zu unterschätzen ist dabei auch der Aspekt, dass wir uns mit einer solchen App und ihrer Infrastruktur schon heute für eventuelle künftige Pandemien rüsten können. Dass die erste Umsetzung sich durch die umfangreichen Diskussionen um Privatheit und Datenschutz verzögerte, mag im Augenblick ein Nachteil sein. Auf lange Sicht hat dies aber doch auch sehr positive Auswirkungen.