
Die Erfolge von maschinellem Lernen basieren auf dem Training der Algorithmen mit möglichst umfangreichen und realistischen Daten. Unternehmen wie Facebook oder Google sind hier klar im Vorteil – schließlich sitzen sie auf unermesslichen Datenschätzen. Dabei wird jedoch dem Schutz sensibler, persönlicher Daten zu wenig Aufmerksamkeit gewidmet. Neuartige Angriffe auf Machine-Learning-Systeme zeigen, dass unsere Daten dort ganz und gar nicht sicher sind.
Autor: Stefan Achleitner; Aufmacherbild: (C) Pixabay/ahmedgad; CC0
Maschinelles Lernen hält Einzug in immer Bereichen unseres täglichen Lebens. Sei es die automatische Spracherkennung am Mobiltelefon, Gesichtserkennung auf Social-Media Plattformen oder die Vorhersage von Krankheitsbildern in der Medizin.
Wie gut ein Modell funktioniert, das auf maschinellem Lernen basiert, hängt vor allem von der Anzahl der Datensätze ab, die zum Trainieren eines solchen Modells zur Verfügung stehen. Aus diesem Grund sind Unternehmen wie Facebook oder Google auch in diesem Bereich so erfolgreich. Die Rechtschreibkorrektur bei Google oder die Gesichtserkennung von Fotos auf Facebook funktionieren besonders gut, weil für das Training der dahinter stehenden Machine-Learning-Systeme eine riesige Anzahl an Daten genutzt werden kann.
Man könnte nun annehmen, dass allein zum Training eingesetzte Daten niemals öffentlich bekannt werden oder rekonstruiert werden können. Doch wie der folgende Artikel zeigt, ist dies leider nicht immer der Fall.
Machine Learning produziert letztlich komplexe mathematische Formeln
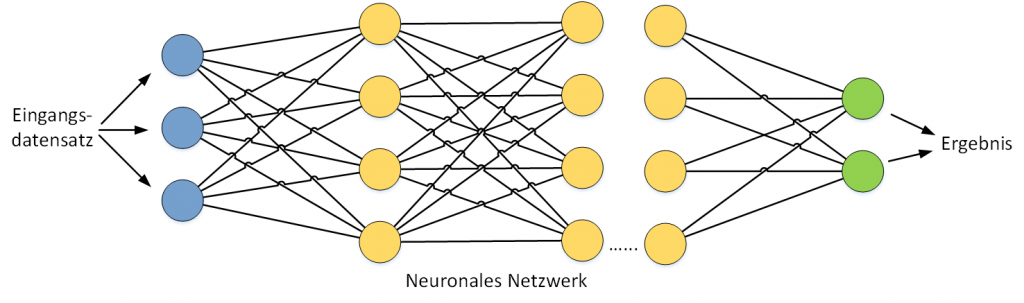
Grundsätzlich wird ein Modell zum maschinellen Lernen, zum Beispiel ein neuronales Netzwerk, mit einer hohen Anzahl von Datensätzen trainiert. Dabei ist für jeden Eingangsdatensatz ein bestimmtes Ergebnis bekannt.
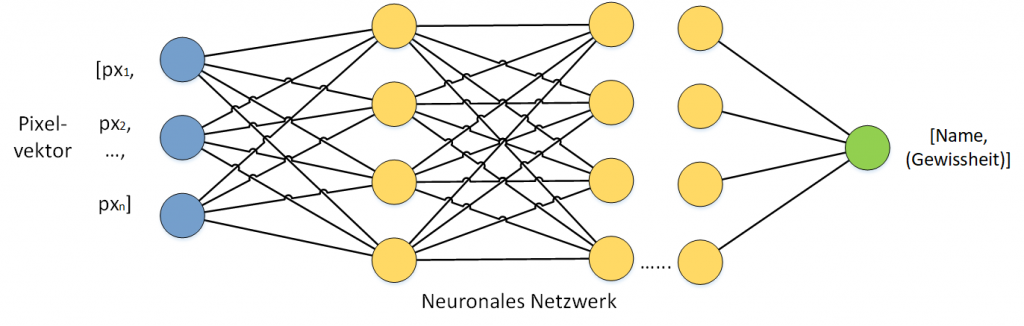
Bei der Gesichtserkennung werden als Eingangsdatensatz die Pixel eines Bildes in Form von Vektoren analysiert. Als Ergebnis wird der Name der dazugehörigen Person ausgegeben. Bei der Anwendung solcher Modelle wird neben dem eigentlichen Ergebnis (dem Namen einer Person) üblicherweise auch eine Gewissheit angegeben. Dieser Wert beschreibt, wie sicher sich das Modell ist, dass ein bestimmtes Eingangsbild wirklich die mit dem Namen identifizierte Person darstellt. Der Wert für die Gewissheit ist eine Fließkommazahl zwischen 0 und 1. Dabei entspricht 1 der vollen Gewissheit.
Bei dem Trainingsprozess werden bestimmte Eigenschaften der Trainingsdatensätze im Modell gespeichert. Solche Trainingsdatensätze, die aus einer Reihe von Eigenschaften und einem zugeordneten Ergebnis bestehen, können oft sehr sensible Information enthalten. Beispielsweise ein Krankheitsbild oder eben eine Reihe von privaten Fotos bestimmter, echter Personen.
Der Trainingsprozess eines Maschine-Learning-Modells ist nichts anderes als die Erstellung einer mathematischen Funktion, die für bestimmte Eingangsvariablen das gewünschte Ergebnis berechnet. Bei der Bilderkennung werden die Eingangsdaten (ein Vektor von Pixelwerten) in ein Ergebnis transformiert – in diesem Fall der Name der zu erkennenden Person.
Aus Ergebnis und Gewissheitsfaktor lassen sich die Trainingsdaten rekonstruieren
Forscher haben nun demonstriert, dass eine solche Funktion zu einem hohen Grad rekonstruiert werden kann. So können sie die Trainingsdatensätze des Maschine-Learning-Modells zurückberechnen. Hierbei nutzen die Forscher den bereits erwähnten Wert für die Gewissheit aus – also die vom Modell angegebene Sicherheit, dass zum Beispiel ein Eingangsbild tatsächlich dem ausgegebenen Namen zuzuordnen ist.
Aus Sicht von Mathematikern lässt sich mithilfe dieses Faktors ein Optimierungsproblem formulieren. Sein Ziel ist es, für einen Pixelvektor (der das Eingangsbild darstellt) die Gewissheit zu maximieren, dass dieses Bild dem Namen einer Person entspricht. Der genaue Algorithmus zur Rückberechnung eines solchen Eingangsbildes wird im Forschungspaper „Model Inversion Attacks that Exploit Confidennce Information and Basic Countermeasures“ im Detail erklärt.
Im Falle eines Modells zur Gesichtserkennung lässt sich damit anhand eines bekannten Namens einer Person das ungefähre Bild berechnen, das zum Trainieren des Modells verwendet wurde. So ein mathematischer Angriff ist eine enorme Verletzung der Privatsphäre von Nutzern verschiedener Plattformen wie Facebook oder Amazon. In dem bereits genannten Forschungspaper „Model Inversion Attacks that Exploit Confidenne Information and Basic Countermeasures“, das auf der Konferenz für Computer and Communication Security vorgestellt wurde, wird dieser Angriff demonstriert.


Obwohl die Rekonstruktion des Bildes, das zum Training verwendet wurde, nicht perfekt ist, lässt sich in bis zu 90 Prozent der Fälle die gezeigte Person auf so einem Bild erkennen.
Gegenmaßnahme für höheren Datenschutz: Gewissheitsfaktoren ungenauer angeben
Da Modelle zur Gesichtserkennung schon vielfach in der Praxis eingesetzt werden, ist es nur eine Frage der Zeit, bis gut ausgebildete Hacker solche Art der Angriffe auch ausführen. Hierbei gilt, wie auch sonst in der Computersicherheit: je mehr ein Angreifer über ein System oder ein Modell weiß, desto erfolgreicher kann ein Angriff ausgeführt werden. Im Falle von Modellen, die auf maschinellem Lernen basieren, ist der ausgegebene Wert über die Gewissheit eines Ergebnisses von großer Bedeutung. Die Autoren des beschriebenen Angriffs melden, dass schon bei einer kleinen Verfälschung dieses Wertes die Rekonstruktion eines Bildes, das zum Trainieren verwendet wurde, fehlschlägt.
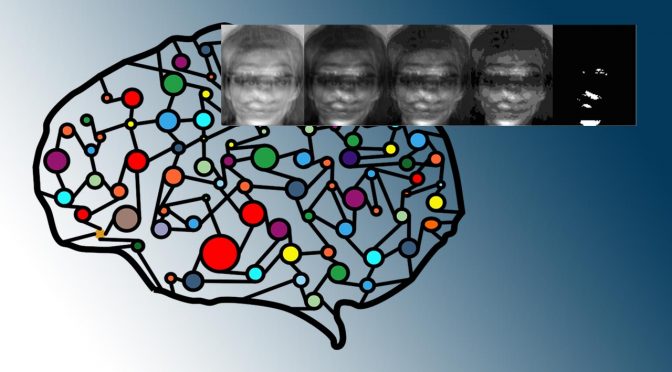
Eine wirkungsvolle Verteidigung gegen einen solchen Angriff wäre also zum Beispiel, nur einen gerundeten oder abgestuften Wert über die Gewissheit eines Ergebnisses anzugeben wie in der folgenden Abbildung für eine Reihe von Rundungsabständen gezeigt wird.

Wie gut zu erkennen ist, wird schon bei einer kleinen Verfälschung durch Runden des Gewissheitsfaktors die Rekonstruktion eines Trainingsbildes erheblich erschwert.
Publikationen wie diese zeigen jedoch, dass der Sicherheit und Privatheit von Daten, die beim maschinellen Lernen verwendet werden, große Beachtung geschenkt werden muss. Dies gilt umso mehr, je häufiger solche Systeme in der Praxis zum Einsatz kommen.