

Daten sind das neue Gold – der Erfolg großer Internet- und Technologiekonzerne wie Google oder Apple basiert nicht zuletzt auf dem Zugang zu einer Unmenge an Nutzerdaten. Die Internet-Konzerne können Datenanalysen gezielt einsetzen, um ihre Produkte zu verbessern beziehungsweise für die Nutzer attraktiver zu machen. Doch dem steht die zunehmend vehementere Forderung gegenüber, die Privatsphäre der Nutzer zu schützen oder sogar technisch zu garantieren. Dabei ist es gar nicht so einfach, diese Forderung zu erfüllen. Große Hoffnungen setzen Informatiker auf das Konzept „Differential Privacy“.
Autor: Stefan Achleitner; Aufmacherbild: (C) Pixabay/JanBaby; CC0
Im Jahr 2006 schrieb der Streaming-Dienst Netflix einen Wettbewerb aus: den „Netflix Prize“. Gesucht wurde der beste Vorhersage-Algorithmus, mit dem Netflix seinen Nutzern möglichst passende Vorschläge für Filme und Serien bieten konnte. Um die Qualität dieser Vorschläge zu verbessern, lobte der Dienst ein Preisgeld von einer Million Dollar aus. Mit Blick auf den Schutz der Privatsphäre seiner Nutzer sollte sich die Aktion für Netflix zu einem Desaster entwickeln.
Vermeintlicher Datenschutz kann völlig unwirksam sein
Damit Entwickler ihre Vorhersage-Algorithmen trainieren, testen und optimieren konnten, stellte Netflix 500.000 Datensätze von echten Nutzern ihrer Plattform zur Verfügung. Diese Daten bestanden aus einem anonymisierten Benutzernamen, Filmtitel, Datum der Bewertung und Bewertung. Um die Privatsphäre seiner Nutzer zu gewährleisten stellte Netflix nur einen Bruchteil der Bewertungen eines bestimmten Nutzers zur Verfügung und veränderte zudem noch zufällige Bewertungen in dem Datensatz.
Auf den ersten Blick schien dies eine sichere Anonymisierung der Datensätze zu sein. Doch der Schutz stellte sich bald als völlig unwirksam heraus: Forscher der Universität Texas demonstrierten in ihrem Paper „Robust De-anonymization of Large Sparse Datasets“, dass sie bis zu 90% der anonymisierten Netflix-Datensätze den tatsächlichen Personen zuordnen können.
Wie ist das möglich? Die Forscher verwendeten Daten aus der öffentlich zugänglichen Internet Movie Database (IMBD). Da IMBD sehr ähnliche Daten wie die Sammlung von Netflix bereitstellt, nämlich die Bewertung von Filmen durch bestimmte Nutzer, lassen sich die anonymisierten Netflix-Bewertungen durch teilweise überschneidende Datensätze den öffentlichen Nutzerprofilen der IMBD zuordnen.
Verknüpfung unterschiedlicher Datensätze bedroht die Privatsphäre
Auch wenn die persönliche Präferenz für bestimmte Filme und Serien auf Netflix zunächst nicht sonderlich sensibel erscheint, lässt sich aus diesen Daten doch auf die Vorlieben eines konkreten Nutzers schließen. Aus solchen Informationen lassen sich dann wiederum zum Beispiel Einschätzungen über die politische Gesinnung ableiten. Oder sie lassen sich für sogenanntes Social Engineering missbrauchen – eine der erfolgreichen Techniken, um bei Cyber-Angriffen technische Schutzmaßnahmen auszuhebeln.
Informatiker bezeichnen solche Angriffe, die auf der Verknüpfung eigentlich voneinander unabhängiger Datensammlungen beruhen, als „Linkage Attacks“. Sie lassen sich auf alle möglichen Szenarien anwenden – darunter auch überaus kritische und sensible Bereiche. So lassen sich auf diese Weise zum Beispiel medizinische Daten de-anonymisieren und realen Personen zuordnen.
Sicherheitsforscher haben deshalb lange darüber nachgedacht, wie sich diese Gefahr verringern lässt. Ihre bislang vielversprechendste Antwort heißt „Differentielle Privatsphäre“. In der IT-Welt üblicher ist die englische Bezeichnung „Differential Privacy“.
Differential Privacy kann Datensätze technisch vor De-Anonymisierung schützen
„Differential Privacy“ hat das Ziel, die Privatsphäre von Datensätzen bei statistischen Abfragen sicherzustellen – zumindest bis zu einem gewissen Maß. Das Grundprinzip hinter diesem Ansatz ist, dass die Daten einer einzelnen Person bei ausreichend großer Datenmenge das Ergebnis einer statistischen Abfrage nicht beeinflussen sollte. Mit anderen Worten: Ob in einer Datenbank mit personenbezogenen Informationen ein Datensatz zu einer einzelnen Person vorhanden ist oder nicht, sollte das Ergebnis der statistischen Abfrage nicht nennenswert verändern.
Um Datenbanken mit „Differential Privacy“ zu schützen, werden die gespeicherten Daten durch „Rauschen“ verfälscht sowie durch sogenannte „Dummy-Einträge“, also Pseudodaten, ergänzt. Statistisch betrachtet dürfen diese Pseudodaten jedoch nicht von den Originaldaten unterscheidbar sein, damit von einzelnen Einträgen keine Rückschlüsse auf andere, zu den Originaldaten gehörende Einträge, möglich sind.
Um dies an einem praktischen Beispiel zu verdeutlichen: Die beiden Datenbanken D1 und D2 (siehe Abbildung) unterscheiden sich um höchstens einen Eintrag. D1 enthält drei Originaldatensätze, D2 zusätzlich einen weiteren Dummy-Eintrag. Wird nun eine statistische Abfrage in D1 oder in D2 durchgeführt, muss die Wahrscheinlichkeit für ein bestimmtes Ergebnis möglichst gleich sein.
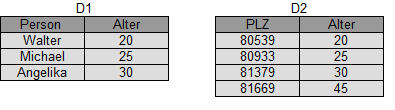
Im abgebildeten Beispiel ist dies nicht der Fall – die Abfrage etwa des Durchschnittsalters würde in D1 und D2 unterschiedliche Antworten liefern. Mit weiteren statistischen Abfragen könnte man nun Rückschlüsse vom einen auf den anderen Datensatz ziehen – Differential Privacy wäre in diesem Fall also nicht gewährleistet.
Datenabfragen und Analysen werden mit Differential Privacy komplexer
Um die Privatsphäre nun doch sicherzustellen, muss die statistische Abfragefunktion so verändert werden, dass die Wahrscheinlichkeit eines bestimmten Ergebnisses gleich bleibt. Anders betrachtet sollte ein bestimmter Eintrag nur mit einer gewissen Wahrscheinlichkeit berücksichtigt werden. In der Informatik spricht man von der sogenannten ε-differentiellen Privatsphäre. Der Faktor ε (Epsilon) ist dabei ein Maß dafür, wie groß die Garantie auf Datenschutz ist.
Wie unser einfaches Beispiel schon zeigt, macht Differential Privacy die Abfragen zum Teil erheblich komplexer. Gleichzeitig werden die Anwendungsmöglichkeiten der Daten eingeschränkt. Obwohl Differential Privacy tatsächlich Datenschutz gewährleisten kann, stößt die Anwendbarkeit leicht an Grenzen. Denn eine zu hohe Verfälschung der Abfragefunktionen kann diese für bestimmte Analysen unbrauchbar machen.
Doch gerade für den Bereich des maschinellen Lernens. wo Algorithmen auf Basis verschiedener Kenndaten großer Datensätze trainiert werden, sind Methoden wie Differential Privacy enorm wichtig. Dies ist vor allem im Hinblick auf ein steigendes Bewusstsein von Privatsphäre und neuer Gesetzeslagen in vielen Ländern von großer Bedeutung. Internet- und Technologiekonzerne müssen darauf achten, die gesetzlichen Vorgaben einzuhalten – gleichzeitig hängt ihr Erfolg stark von der Nutzbarkeit der User-Daten ab.
Dass allein der Zugang zu einem Modell von Machine-Learning ermöglicht, Datensätze zu rekonstruieren und damit eine starke Verletzung der Privatsphäre darstellen kann, haben wir bereits in einem früheren Artikel beschrieben. Deshalb engagieren sich die Technologie-Konzerne stark in der Forschung zu Differential Privacy. Denn dieses Konzept kann einen wichtigen Beitrag leisten, um sowohl die Privatsphäre der Nutzer zu schützen als auch Vorteile aus der tiefen Analyse von Benutzerdaten weiter erfolgreich nutzen zu können.