

Aufmacherbild: (C) The Digital Artist, Pixabay, CC0
Autor: Stefan Achleitner
Maschinelles Lernen und Künstliche Intelligenz sind zurzeit in aller Munde. Denn diese Technologien erlauben riesige Fortschritte bei Anwendungen von komfortablerer Bilderkennung in Consumer-Software bis hin zum Autonomen Fahren. Doch wenn Computer Entscheidungen treffen, und der Mensch oft gar nicht mehr im Detail weiß, auf welcher Basis sie zu ihrer Schlussfolgerung gekommen sind, stellt sich schnell auch die Frage: Wie sicher sind diese Mechanismen gegen Manipulationen und unberechtigte Eingriffe? Oder kurz: Wie sicher ist Machine Learning?
Um die Gefahren und Bedrohungen besser einschätzen zu können, zunächst einige wichtige Grundlagen im Schnelldurchlauf:
Maschinelles Lernen oder englisch „Machine Learning“ ist ein Teilbereich der Forschung über künstliche Intelligenz. Man versteht darunter die Konstruktion von Algorithmen auf Basis von Daten. Anders als die klassische Programmierung, die einem streng statischen Ablauf an Befehlen folgt, treffen Machine-Learning-basierte Algorithmen Entscheidungen und Vorhersagen aufgrund einer Datenbasis.
Drei Kategorien von Machine Learning
Algorithmen für maschinelles Lernen lassen sich grob in drei Kategorien unterteilen: „Supervised Learning“, „Unsupervised Learning“ und „Reinforcement Learning“.
Beim „Supervised Learning” wird der Algorithmus mit einem Datensatz von Eingaben (Inputs) und Ausgaben (Outputs) trainiert. Die Aufgabe des Algorithmus besteht drin, ein „Mapping“ – also eine Zuordung der Eingangs- und Ausgangspaare – zu finden. Ist ein solcher Algorithmus entsprechend trainiert, kann er auf einen Eingangsdatensatz, für den noch keine Ausgaben existieren, angewandt werden. Solche Algorithmen werden oft zur Klassifizierung von Inhalten, zum Beispiel zur Bilderkennung, verwendet.
Beim „Unsupervised Learning” wird nur ein Eingangsdatensatz verwendet. Der Algorithmus hat dann die Aufgabe, Muster und Kategorien zu identifizieren.
„Reinforcement Learning” ist eine Methode, die dem menschlichen Lernprozess am nächsten kommt. Hier hat der Algorithmus eine bestimmte Aufgabe und erhält durch die Interaktion mit seiner Umwelt Feedback – konkret eine Belohnung oder eine Bestrafung. Je länger der Algorithmus mit der Umwelt interagiert, desto besser kann er seine Aufgabe erfüllen. Solche Arten von Algorithmen werden zum Beispiel für das autonome Fahren eingesetzt, um reale Verkehrssituationen einzuschätzen.
Wie funktionieren neuronale Netzwerke?
Für die verschiedenen Kategorien gibt es verschiedene Algorithmen, die auf die genannten Lernprobleme angewendet werden können. Beispiele dafür sind „decision trees“, „support vector machines“ oder künstliche neuronale Netzwerke („artificial neural networks“ oder einfach „neural networks”).
Vor allem neuronale Netzwerke werden in letzter Zeit auf eine wachsende Anzahl von Problemen angewandt, da sie komplexe Aufgaben sehr gut bewältigen können. Neuronale Netzwerke sind Netzen von Nervenzellen im menschlichen Gehirn nachempfunden. Daher stammt auch ihr Name.
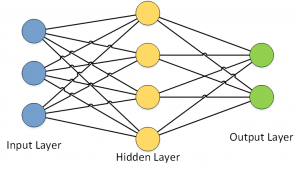
Ein Neuronales Netzwerk besteht grundsätzlich aus einer Eingangschicht (Englisch: Input Layer), einer verborgenen Schicht (Hidden Layer) und einer Ausgangsschicht (Output Layer).
Als einfaches Beispiel kann man sich ein neuronales Netzwerk vorstellen, das basierend auf den Eingangswerten, Körpertemperatur, Kopfschmerzen und Müdigkeit eine Vorhersage erstellt ob eine Person krank ist oder nicht.
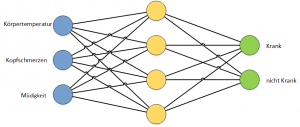
Um so eine Vorhersage tätigen zu können muss das Netzwerk vorher trainiert werden, also lernen. In dem gezeigten Beispiel würde man das Prinzip des „supervised learning“ anwenden und das Netzwerk mit einem existierenden Datensatz von Eingangs- und Ausgangswerten trainieren.
Bei diesem Trainingprozess, man spricht hier auch von „back propagation“, werden Faktoren („weights“) für die Verbindungen und „bias“ für die Knoten errechnet.
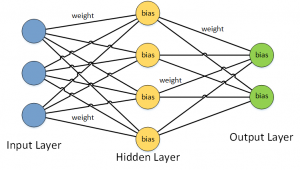
Ist ein Netzwerk trainiert, lässt sich mit Hilfe der existierenden Faktoren, „weights“ und „biasses“, eine Prognose für einen Eingangsdatensatz erstellen. Hierbei werden aus den Eingangswerten und den Faktoren der Verbindungen und Knoten neue Werte errechnet, die dann schrittweise zu einem Ergebnis im output layer führen. Dieses Prinzip bezeichnet man auch als „forward propagation“.
Das gezeigte neuronale Netzwerk ist ein sehr einfaches Beispiel für ein Klassifizierungsproblem. Aufgaben, die um vieles komplexer sind und eine hohe Anzahl von Eingangs- und Ausgangsknoten haben, zum Beispiel Gesichtserkennung, können mit neuronalen Netzwerken oft sehr gut gelöst werden. Hierbei spielt aber die Anzahl und Qualität der verfügbaren Trainingsdaten eine wichtige Rolle.
Einen Schritt weiter: Deep Neural Networks
Für komplexe Probleme werden immer öfter sogenannte „deep neural networks“ eingesetzt. Man spricht in diesem Zusammenhang häufig auch von „deep learning“. Im Gegensatz zu einfachen neuronalen Netzen, wie im oben vorgestellten Beispiel, haben „deep neural networks“ mehrere verborgene Schichten.
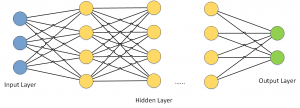
Das Trainieren von „deep neural networks“ kann sehr viel Zeit kosten und Wochen bis sogar Monate in Anspruch nehmen. Grafikprozessoren (GPUs) können diese Aufgabe im übrigen viel effizienter erledigen als normale Prozessoren (CPUs).
Um ein „deep neural network“ zu trainieren werden oft Millionen von Datensätzen benötigt, um die Faktoren der Verbindungen und Knoten im Netzwerk errechnen zu können.
Ein großer Unterschied zu traditionellen Algorithmen ist, dass das Ergebnis eines neuronalen Netzwerks oft nicht einfach nachvollzogen werden kann. Bei Algorithmen, die traditionell implementiert sind, besteht die Möglichkeit, Schritt für Schritt nachzuverfolgen, was genau passiert und wie ein Ergebnis zustande kommt. Dieser Prozess des sogenannten „Debuggings“ ist bei neuronalen Netzen nur sehr schwer möglich.
Wo gibt es mögliche Sicherheitlücken?
Ein relativ junges Forschungsfeld ist die Sicherheit von neuronalen Netzwerken und Machine Learning im Allgemeinen. Dabei werden zum Beispiel Angriffsszenarien untersucht wie die Frage, ob ein Angreifer in der Lage sein könnte, einen Eingangsdatensatz wie etwa ein Bild so zu manipulieren, dass die Veränderungen für das menschliche Auge nicht zu erkennen sind, das neuronale Netzwerk aber eine Fehlprognose erstellt.
Das dies mit nur kleinsten Veränderungen an einem Objekt möglich ist, haben Forscher vor kurzem gezeigt. Das wissenschaftliche Paper dazu ist hier verfügbar. Oft genügt es hierbei schon, nur die Farbe einzelner Pixel zu ändern.
Wenn selbstfahrende Autos beispielsweise mit Machine-Learning-Algorithmen Verkehrsschilder analysieren, werden mögliche Manipulationen schnell bedrohlich: Würde etwa ein Stoppschild von einem Angreifer so verändert, dass es als Vorfahrtschild interpretiert wird, könnte dies zu schweren Unfällen führen.
Der Grund warum solche Angriffe grundsätzlich funktionieren: Es ist oft schwer nachzuvollziehen, warum ein neuronales Netzwerk zum Beispiel ein Bild eines Stoppschilds als Stoppschild erkennt. Möglicherweise wird das Stoppschild aufgrund der Anordnung von roten und weißen Farbpixeln erkannt. Grundsätzlich dieselben Eigenschaften hätte dann aber auch ein Vorfahrtschild. Ob beispielsweise die sechseckige Form eines Stoppschilds vom neuronalen Netzwerk miteinbezogen wird oder nicht, ist den Forschern oft gar nicht bekannt. Es ist anzunehmen, dass dies von Faktoren wie etwa dem genauen Trainingsdatensatz abhängt.
Und es gibt noch weitere Sicherheitsbedenken – etwa zum Datenschutz, weil die Trainingsdaten im Machine-Learning-Algorithmus verankert sind. Oder: Wie lässt sich verhindern, dass der Algorithmus „Vorurteile“ entwickelt – also gegenüber bestimmten Eingangsdaten voreingenommen ist?
Um Verteidigungsstrategien gegen solche Angriffe und Manipulationen entwickeln zu können und Machine-Learning-Algorithmen gegen solche möglichen Sicherheitslücken zu härten, ist der erste Schritt, die gerade skizzierten Angriffszenarien zu verstehen und Schutzmaßnahmen dagegen zu entwickeln.
Ein Experte im Bereich Sicherheit von maschinellem Lernen ist Nicolas Papernot, Doktoratsstudent an der Pennsylvania State University und Gewinner des Google PhD Fellowships für Sicherheitsforschung von maschinellem Lernen. Das folgende, rund 11-minütige Videointerview vertieft die hier skizzierten Fragestellungen:
Wie sieht die Zukunft von maschinellem Lernen aus?
2016 hat das Marktforschungsinstitut Gartner maschinelles Lernen als Technologie identifiziert die im Moment am meisten „gehypt“ wird, was unrealistische Erwartungen an diese Technologie zur Folge habe.
Doch wie gerade schon geschildert: Zunehmend mehr Produkte und Funktionen werden in Zukunft auf diesem Prinzip basieren. Weil es dabei um oft kritische oder folgenschwere Entscheidungen geht, müssen Forscher sich auch mit den gerade beschriebenen Sicherheitsfragen zunehmend intensiv beschäftigen. Da ist es ein Stück weit beruhigend, dass diese Fragen längst erkannt wurden und Forscher weltweit an belastbaren Antworten darauf arbeiten.