

Elemente Aufmacherbild: Eric Gaba – Wikimedia Commons user: Sting (CPU), MrNick2018 (Spectre), Natascha Eibl (Meltdown), CC BY-SA 3.0
Autor: Stefan Achleitner
Die Angriffe Spectre und Meltdown haben Anfang des Jahres die Sicherheit vieler Computersysteme erschüttert, da sie Schwachstellen der Architektur von weit verbreiteten Prozessoren ausnützen. Schon seinerzeit warnten Sicherheitsforscher, dass diesen ersten bekannt gewordenen Angriffen noch weitere Varianten folgen dürften. Diese Befürchtung erfüllt sich nun. Im Folgenden zeigen wir an einem Beispiel, wie solche Abwandlungen funktionieren – und wie ihnen begegnet werden kann.
In der Vergangenheit wurde Hardware wie zum Beispiel Prozessoren vor allem mit Hinblick auf hohe Performance entwickelt. Sicherheit wurde hierbei vergleichsweise wenig Beachtung geschenkt. Die rächt sich nun durch immer ausgeklügeltere Angriffe auf die Architektur moderner Mikroprozessoren.
Angriffsziel Spekulative Ausführung
Der grundsätzliche Mechanismus, den Meltdown und Spectre angreifen, ist die spekulative Ausführung in modernen Prozessoren. Die CPUs rechnen mögliche Verzweigungen und Programmabläufe „auf Verdacht“ durch. Lagen sie richtig, haben sie Zeit gespart, weil bei der tatsächlichen Anforderung bestimmter Berechnungen deren Ergebnisse schon vorliegen. Diese Technik ist nicht grundlegend schlecht, denn ohne sie würden Programme erheblich langsamer laufen. Die steigende Anzahl von Angriffen auf die Hardwarearchitektur der Prozessoren zeigt jedoch, dass auf jeden Fall eine engere Zusammenarbeit zwischen Hardware- und Softwareherstellern erforderlich ist.
Bislang wurde die Ausnutzung der beschriebenen Schwachstellen „auf freier Wildbahn“ zwar noch nicht beobachtet. Doch dies dürfte nur noch eine Frage der Zeit sein. Zumal der Schadcode sogar durch den Aufruf von Webseiten und somit über den Web-Browser in den Computer gelangen kann. Die Forscher Giorgi Maisuradze und Christian Rossow von der Universität des Saarlandes beschreiben in einem Paper, das auf der Internationalen Konferenz für Computer- und Kommunikationssicherheit (CCS 2018) im Oktober in Toronto vorgestellt wird, wie solche Angriffe aussehen können.
Neue Angriffsvariante: Überschreiben des Return Stack Buffers
Im speziellen wird dabei die Funktion sogenannter Return Stack Buffers (RSBs) ausgenutzt. Sie haben in Prozessoren die Aufgabe, die Aufruf- und Rücksprungadressen von Instruktionen zu speichern. RSBs dienen vor allem dazu, die Genauigkeit bei der Vorhersage von Sprungadressen während der Ausführung von Programmfunktionen zu erhöhen. Dazu werden je nach Prozessorarchitektur zwischen 16 und 32 Rücksprungadressen gespeichert.
Einträge im RSB-Speicher werden immer dann geändert, wenn der Prozessor eine Unterfunktion aufruft. Beim Aufruf der Unterfunktion wird ein neuer Eintrag hinzugefügt. Ist die Ausführung beendet, springt der Prozessor an die Speicheradresse zurück, von der aus der Aufruf ursprünglich erfolgt ist. So kann das dort ablaufende Hauptprogramm nach Abarbeitung der Unterfunktion weiter ausgeführt werden.
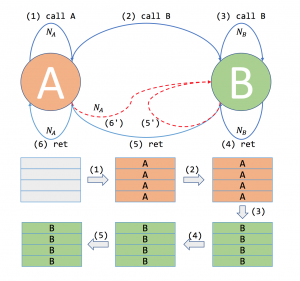
Da RSBs wie erwähnt ein bestimmtes Speicherlimit haben, kann dieser Mechanismus absichtlich gestört werden. Wie dies konkret möglich ist, erklären die Forscher in ihrem Paper.
Der Angriff basiert auf der Nutzung von zwei Funktionen, A und B. Vereinfacht beschrieben wird die Funktion A „rekursiv“, also immer wieder durch sich selbst aufgerufen. Dadurch entsteht eine Verschachtelung von Funktionsaufruf- und Rücksprungadressen. Am tiefsten Punkt des rekursiven Aufrufs ruft A die Funktion B auf, welche sich selbst nun rekursiv so oft aufruft, wie Adressen in den RSB-Speicher passen – also zum Beispiel 16 mal. Dadurch werden alle Einträge im RSB überschrieben. Springt nun die Funktion B aus den verschachtelten Aufrufen wieder zurück, müsste beim letzten Rücksprung wieder der Kontext (insbesondere die Speicherinhalte in den Prozessorregistern) von Funktion A aufgerufen werden. Da aber alle Einträge des RSB’s durch B belegt sind, erfolgt bei diesem letzten Rücksprung eine Fehlspekulation. Der Rücksprung wird zwar nicht grundsätzlich verhindert – aber in den Speicherregistern des Prozessors stehen nicht mehr die Werte, die zu Funktion A gehören, sondern die von Funktion B.
Durch die erzwungenen wiederholten Fehlvorhersagen erfolgt eine Art Verwirrspiel, das es ermöglicht, bestimmte Sicherheitsmaßnahmen zu umgehen. Ein Angreifer, der beide Funktionen A und B kontrolliert, kann so auf für ihn eigentlich nicht zugängliche Speicherbereiche zugreifen und somit unter Umständen sensible Daten auslesen.
Dass dieses Szenario nicht nur in der Theorie bedrohlich ist, zeigen die Autoren des Papers mit einer Demonstration anhand einer Skripting-Sprache, die von allen modernen Web-Browsern ausgeführt werden kann. Eine vom Angreifer kontrollierte Webseite führt ein Script aus, das die Funktionsweise von A und B hat. Durch dieses Prinzip kann ein Angreifer unter Umständen Daten von Webseiten auslesen, die in anderen Browser-Fenstern laufen. Wenn man sich vorstellt, dass dort ein E-Mail-Dienst oder die Webseite einer Bank genutzt werden, zeigt sich, dass der praktische Zugriff auf vertrauliche und kritische Daten absolut realistisch ist.
Verteidigung kann auf mehreren Ebenen erfolgen
Die Autoren schlagen jedoch auch Verteidigungs-Strategien vor, mit denen das beschriebene Angriffsprinzip abgewehrt werden kann. Dazu gibt es mehrere Möglichkeiten auf verschiedenen Ebenen.

Auf Hardware-Ebene könnte der Angriff durch Deaktivieren von spekulativer Ausführung verhindert werden. Der große Nachteil dieser Lösung ist jedoch, dass dadurch die Ausführung von Programmen deutlich langsamer wird. Denn die Kommunikation zwischen Prozessor und Speicher stellt einen „Flaschenhals” dar, der ohne spekulative Ausführung noch enger wird. Prozessorentwickler denken allerdings schon darüber nach, spekulative Ausführung gezielt für bestimmte kritische Funktionen oder Tasks zu unterbinden. Angedacht ist zum Beispiel, dass künftige Mehrkern-Prozessoren zwischen „sicheren“ und schnellen Kernen unterscheiden werden. In aktuellen CPU-Modellen ist dies jedoch noch nicht der Fall.
Eine weitere Ebene, die Möglichkeiten zur Verteidigung bietet, ist die Compiler-Ebene – also die Übersetzung des Programmcodes in Maschinensprache. Hierbei könnten künftig Sicherheitsmechanismen eingebaut werden, um zu verhindern, dass eine Funktion im Speicherkontext einer anderen Funktion ausgeführt wird.
Die Autoren diskutieren auch die Möglichkeit, Verteidigungsmechanismen direkt in Web-Browsern einzubauen, um solche Angriffe zu verhindern. Als Beispiel wird hier eine strenge Isolierung verschiedener Ausführungsumgebungen genannt. Dies lässt sich zum Beispiel erreichen, indem für jede Webseite ein eigener Prozess verwendet wird. Solche Sicherheitstechniken nutzt schon heute zum Beispiel der Browser Chrome.
Um die Wirksamkeit solcher Gegenmaßnahmen zu maximieren und auch ihre Performance-Nachteile in Grenzen zu halten, ist jedoch eine Kombination der skizzierten Verteidigungsmechanismen auf allen Ebenen erforderlich.
Detaillierte Beschreibungen des Angriffs und der Verteidigungs-Strategien lassen sich im hier verlinkten Forschungspaper nachlesen.