
Intelligente Spracherkennungssysteme wie von Apple und Google sind nur die Spitze des Eisberges bei semantischen Anwendungen (Teil 1 zu diesem Thema lesen Sie hier). Nach der hochkomplexen Erkennung von Sinn und Kontext muss im Hintergrund die eigentliche Information abgerufen und aufbereitet werden. Das erfordert auch ohne Spracherkennung eine gigantische Rechenleistung. Im Folgenden ein paar Beispiele für intelligente Datenaufbereitung.
 Ob es eine akustische oder klassische „händische“ Abfrage ist: Die Kunst ist es, relevante Daten zu filtern und in Beziehung zueinander zu bringen.
Ob es eine akustische oder klassische „händische“ Abfrage ist: Die Kunst ist es, relevante Daten zu filtern und in Beziehung zueinander zu bringen.
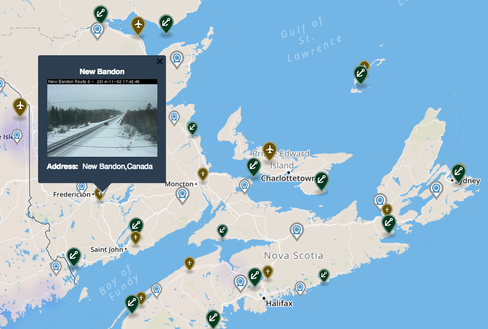
Das Karlsruher Institut für Technologie und die University of Manchester suchen jedes Jahr in einer „Semantic Web Challenge“ die innovativsten Anwendungen. Zu den Preisträgern 2014 zählt Graphofthings.org, die Millionen Echtzeit-Daten über eine Weltkarte abrufbar macht – von Flughäfen über Schiffe bis zu Verkehrskameras und weltweiten Webcams.
 Was vor einigen Jahren noch belächelt wurde, ist jetzt Realität: Predictive Policing. Durch die Auswertung verschiedenster Datenbanken können Ermittler Verbrechen vorhersagen. So sucht das System „Precobs“ in den Daten der Einbrüche der vergangenen Jahre nach Mustern und berechnet die Wahrscheinlichkeit, mit der in einem bestimmten Gebiet ein Einbruch geschehen könnte. Seitdem die Polizei ihre Präsenz in den markierten Gegenden konzentriert, ist die Zahl der Fälle bereits zurückgegangen.
Was vor einigen Jahren noch belächelt wurde, ist jetzt Realität: Predictive Policing. Durch die Auswertung verschiedenster Datenbanken können Ermittler Verbrechen vorhersagen. So sucht das System „Precobs“ in den Daten der Einbrüche der vergangenen Jahre nach Mustern und berechnet die Wahrscheinlichkeit, mit der in einem bestimmten Gebiet ein Einbruch geschehen könnte. Seitdem die Polizei ihre Präsenz in den markierten Gegenden konzentriert, ist die Zahl der Fälle bereits zurückgegangen.
Auch die bekannte Auto-Complete-Funktion von Google gehört zu den semantischen Anwendungen. Sie „ahnt“ das Gesuchte voraus und präsentiert noch vor dem Beginn der Suche mögliche Suchwortkombinationen.
Spracherkennung für verschiedene Aufgabengebiete
Sprachauthentifizierung funktioniert ebenfalls schon erstaunlich gut, beispielsweise durch eine Lösung des Software-Herstellers Nuance: Bankkunden fragen ihren Kontostand ohne PIN-Code telefonisch ab, weil das System die immer unterschiedliche Stimme identifiziert.
Für verschiedene Branchen (Medizin, Jura etc.) hält Nuance optimierte Module für seine preisgekrönte Software „Dragon Naturally Speaking“ bereit. Diese verknüpft Spracherkennung und Textanalyse so, dass der Computer die Bedeutung der gesprochenen Wörter versteht und Texte nahezu fehlerfrei erfassen kann. Eine Firma, die sich auf die Einrichtung und Schulung von Nuance-Lösungen spezialisiert hat, ist zum Beispiel Speechmedia in Essen.
 Einen Schritt weiter geht das medizinische Forschungsprojekt „semanticVOICE“ – hier bekommt der Arzt einen unsichtbaren Helfer, der im Hintergrund die erfassten Daten analysiert. Die Dokumentationen werden mit medizinischem Wissen angereichert und auch auf Plausibilität überprüft.
Einen Schritt weiter geht das medizinische Forschungsprojekt „semanticVOICE“ – hier bekommt der Arzt einen unsichtbaren Helfer, der im Hintergrund die erfassten Daten analysiert. Die Dokumentationen werden mit medizinischem Wissen angereichert und auch auf Plausibilität überprüft.
Spracherkennung, z.B. durch Lösungen der Firma Vocollect, wird auch zunehmend in Distributionszentren und Lagerhäusern eingesetzt – mit Fehlerfreiheitsraten bis zu 99,9 Prozent und Produktivitätszuwächsen von 15 bis 35 Prozent. Ob für Kommissionierung, Qualitätskontrolle, Warenein- und -ausgang: Durch die Sprachdaten erreichen Unternehmen eine höhere Effizienz in der Datenlogistik. Und die Technik „PictureSafe“ sorgt bei der Erfassung des Inhalts für eine automatische Verschlagwortung.
Fazit
Während das Internet, wie wir es als Menschen bisher nutzen, als neue industrielle Revolution gilt, sehen viele Experten semantische Anwendungen als Revolution in der Computerwelt. Wenn man in vielleicht fünf bis zehn Jahren nahezu alles, was man wissen will, in kürzester Zeit finden kann, und das unabhängig von der Art der Eingabe, dann werden wohl die Tage unserer gewohnten klassischen Suchmaschinen gezählt sein.